

Table of Contents
Large language models (LLMs) like Claude, ChatGPT, Gemini, and Llama have completely changed how we interact with information and technology. They can write eloquently, perform deep research, and solve increasingly complex problems. But while typical models excel at responding to natural language, they’ve been constrained by their isolation from real-world data and systems.
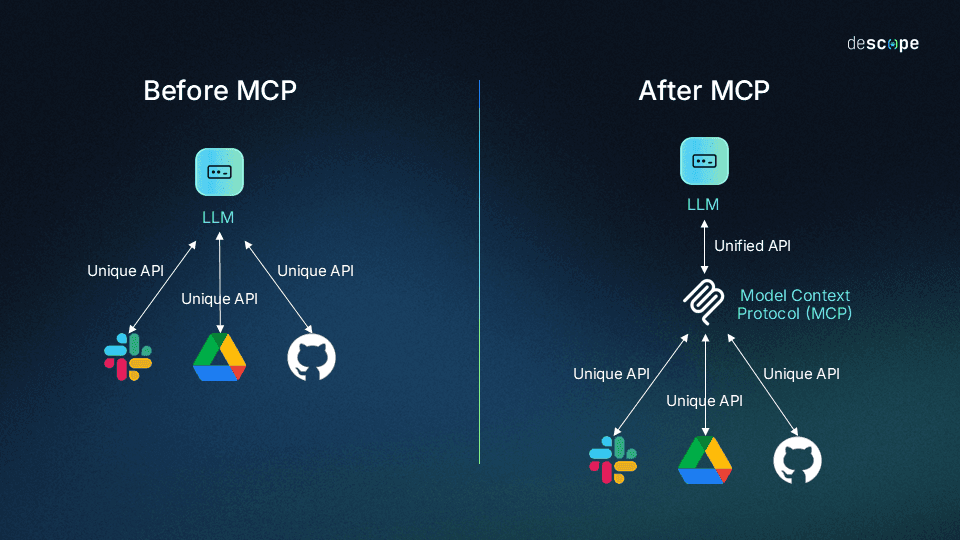
The Model Context Protocol (MCP) addresses this challenge by providing a standardized way for LLMs to connect with external data sources and tools—essentially a “universal remote” for AI. Released by Anthropic as an open-source protocol, MCP builds on existing function calling by eliminating the need for custom integration between LLMs and other apps. This means developers can build more capable, context-aware applications without reinventing the wheel for each combination of AI model and external system.
This guide explains the Model Context Protocol’s architecture and capabilities, how it solves the inherent challenges of AI integration, and how you can begin using it to build better AI apps that go beyond isolated chat interfaces.
LLM isolation & the NxM problem
It’s no secret that LLMs are remarkably capable, but they typically operate in isolation from real-world systems and current data. This creates two distinct but related challenges: one for end users, and one for developers and businesses.
For everyday users, the isolation means a constant “copy and paste tango” to get relevant responses about recent data. This requires manually collecting information from various sources, feeding it into the LLM’s chat interface, and then extracting or applying the AI’s output elsewhere.
While several models offer AI-powered web search, and Anthropic’s Claude 3.7 and 4 models boast a Computer Use feature, they still lack direct integration with knowledge stores and tools. Even as major platforms like OpenAI’s ChatGPT and Google’s Gemini add built-in app integrations, these remain platform-specific solutions rather than universal standards.
For devs and enterprises, the challenge is much more complex: the “NxM problem,” where N represents LLMs and M stands for tools. On the N side, there are many AI systems, and on the M side, there are countless systems. Each LLM provider has their own protocols to connect with external tools, making the potential integration points essentially endless.
By breaking the NxM problem down, we can see it causes:
Redundant development efforts: Dev teams will repeatedly solve the same integration issues for each new AI model or data source. For example, connecting ChatGPT with your knowledge stores requires starting from scratch with custom code. But with every additional AI system or tool, your devs have to do everything from the beginning each time—N multiplied by M.
Excessive maintenance: Tools, models, and APIs will inevitably evolve, and business will want to stay on the cutting edge. The lack of standardization means an integration can potentially stop working because a tool or model is updated, or an old one is deprecated.
Fragmented implementation: Different integrations may handle similar functions in totally unexpected ways, creating unpredictable or undesirable results. This fragmentation can lead to end user confusion or frustration as different developers and companies implement inconsistent integrations.
However, it’s important to understand that MCP doesn’t solve the NxM problem by simply replacing the integration methods that came before. It connects AI apps to context while building on top of function calling—the primary method for calling APIs from LLMs—to make development simpler and more consistent.
Relationship between function calling & Model Context Protocol
Function calling, which allows LLMs to invoke predetermined functions based on user requests, is a well-established feature of modern AI models. Sometimes referred to as “tool use,” function calling is not mutually exclusive with MCP; the new protocol simply standardizes how this API feature works, adding context for the LLM. This is achieved by streaming tool definitions (including their capabilities, data stores, and possible prompts) to LLMs from the MCP server.
Without MCP, when you use a function call directly with an LLM API, you need to:
Define model-specific function schemas, which are JSON descriptions of the function, acceptable parameters, and what it returns.
Implement handlers (the actual code that executes when a function is called) for those functions.
Create different implementations for each model you support.
MCP standardizes this process by:
Defining a consistent way to specify tools (functions) across any AI system.
Providing a protocol for discovering available tools and executing them.
Creating a universal, plug-and-play format where any AI app can use any tool without custom integration code.
You might be familiar with AI apps that use function calling, like Custom GPTs using GPT Actions. A Custom GPT can determine which API call resolves the user's prompt, create the necessary JSON, then make the API call with it. While this allows some purpose-built tooling, it’s bound to OpenAI’s ecosystem. MCP brings similar capabilities to any AI application that implements the protocol, regardless of the underlying model vendor.
Also read: MCP vs Function Calling
MCP architecture and core components
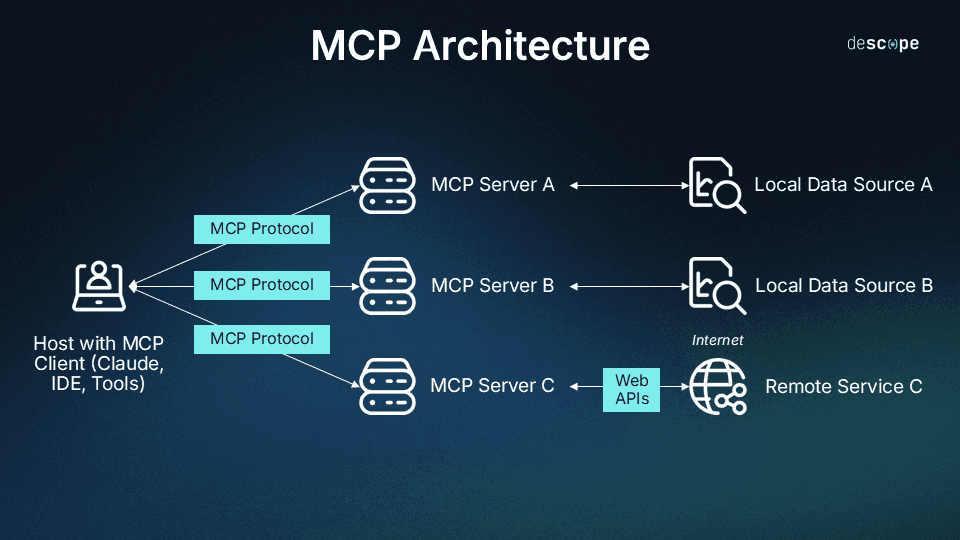
The Model Context Protocol uses a client-server architecture partially inspired by the Language Server Protocol (LSP), which helps different programming languages connect with a wide range of dev tools. Similarly, the aim of MCP is to provide a universal way for AI applications to interact with external systems by standardizing context.
Core components
MCP architecture consists of four primary elements:
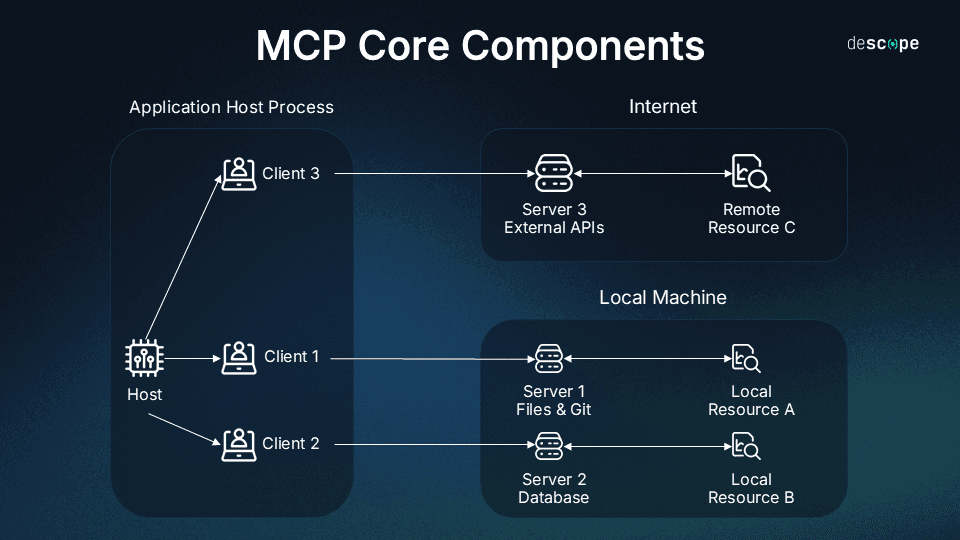
Host application: Applications housing LLMs (or LLMs themselves) that interact with users and initiate connections. This includes Claude Desktop, AI-enhanced IDEs like Cursor, and standard web-based LLM chat interfaces.
MCP client: Integrated within the host application to handle connections with MCP servers, translating between the host’s requirements and the Model Context Protocol. Clients are built into host applications, like the MCP client inside Claude Desktop.
MCP server: Adds context and capabilities, exposing specific functions to AI apps through MCP. Each standalone server typically focuses on a specific integration point, like GitHub for repository access or a PostgreSQL for database operations.
Transport layer: The communication mechanism between clients and servers. MCP supports two primary transport methods:
STDIO (Standard Input/Output): Mainly local integrations where the server runs in the same environment as the client.
HTTP+SSE (Server-Sent Events): Remote connections, with HTTP for client requests and SS for server responses and streaming.
All communication in MCP uses JSON-RPC 2.0 as the underlying message standard, providing a standardized structure for requests, responses, and notifications.
How MCP works
When a user interacts with a host application (an AI app) that supports MCP, several processes occur behind the scenes to enable quick and seamless communication between the AI and external systems. Let’s take a closer look at what happens when a user asks Claude Desktop to perform a task that invokes tools outside the chat window.
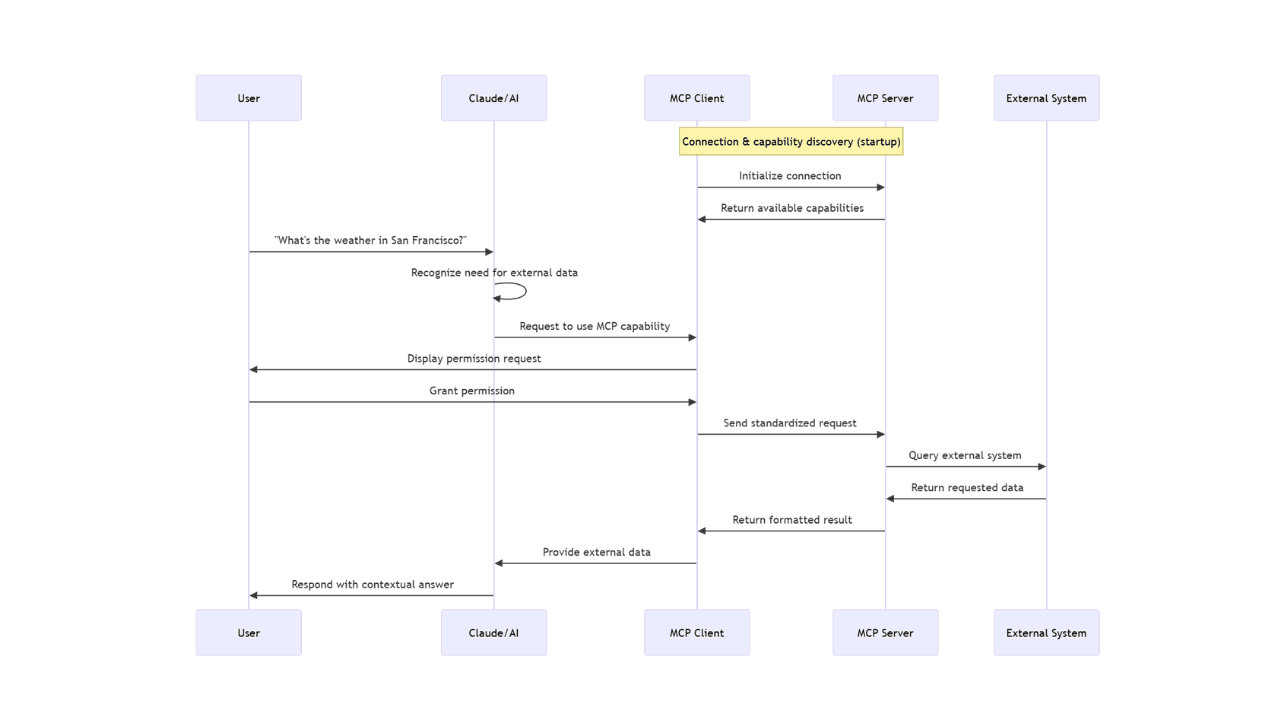
Protocol handshake
Initial connection: When an MCP client (like Claude Desktop) starts up, it connects to the configured MCP servers on your device.
Capability discovery: The client asks each server "What capabilities do you offer?" Each server responds with its available tools, resources, and prompts.
Registration: The client registers these capabilities, making them available for the AI to use during your conversation.
From user request to external data
Let's say you ask Claude, "What's the weather like in San Francisco today?" Here's what happens:
Need recognition: Claude analyzes your question and recognizes it needs external, real-time information that wasn't in its training data.
Tool or resource selection: Claude identifies that it needs to use an MCP capability to fulfill your request.
Permission request: The client displays a permission prompt asking if you want to allow access to the external tool or resource.
Information exchange: Once approved, the client sends a request to the appropriate MCP server using the standardized protocol format.
External processing: The MCP server processes the request, performing whatever action is needed—querying a weather service, reading a file, or accessing a database.
Result return: The server returns the requested information to the client in a standardized format.
Context integration: Claude receives this information and incorporates it into its understanding of the conversation.
Response generation: Claude generates a response that includes the external information, providing you with an answer based on current data.
Ideally, this entire process happens in seconds, creating an unobtrusive experience where Claude appears to "know" information it couldn't possibly have from its training data alone.
Additional protocol capabilities
Since its initial release, MCP has added several significant functions that enhance its capabilities:
Sampling allows servers to request LLM completions from clients. For example, an MCP server helping with code review could recognize the need for additional context and ask the client’s LLM to generate a summary of recent changes. This enables an essentially “agentic” workflow while still retaining client control over model access, selection, and permissions—all without needing server API keys.
Elicitation enables servers to request additional information from users during their operations. For instance, if the GitHub MCP server needs to know which branch to commit to because it wasn’t described in the prompt, it can ask the user for that information mid-operation using structured JSON schemas to validate the response. This enables more interactive workflows while maintaining security through human oversight.
Roots are a standardized way for clients to expose filesystem boundaries to servers. For example, when using an MCP server for file operations, the client can specify that the server only has access to /user/documents/project/ rather than the entire filesystem, preventing accidental (or malicious) access to sensitive data stores.
MCP client & server ecosystem
Since its introduction in late 2024, MCP has experienced explosive growth. Some MCP marketplaces claim nearly 16,000 unique servers at the time of writing, but the real number (including those that aren’t made public) could be considerably higher.
Examples of MCP clients
The MCP client ecosystem now includes:
Claude Desktop: The original, first-party desktop application with comprehensive MCP client support
Claude Code: Command-line interface for agentic coding, complete with MCP capabilities
Cursor: The premier AI-enhanced IDE with one-lick MCP server installation
Windsurf: Previously known as Codeium, an IDE with MCP support through the Cascade client
Continue: Open-source AI coding companion for JetBrains and VS Code
Visual Studio Code: Microsoft’s IDE, which added MCP support in June 2025
JetBrains IDEs: Full coding suite that added AI Assistant MCP integration in August 2025
Xcode: Apple’s IDE, which received MCP support through GitHub Copilot in August 2025
Eclipse: Open-source IDE with MCP support through GitHub Copilot as of August 2025
Zed: Performance-focused code editor with MCP prompts as slash commands
Sourcegraph Cody: AI coding assistant implementing MCP through OpenCtx
LangChain: Framework with MCP adapters for agent development
Firebase Genkit: Google’s AI development framework with MCP support
Superinterface: Platform for adding in-app AI assistants with MCP functionality
Notably, IDEs like Cursor and Windsurf have turned MCP server setup into a one-click affair. This dramatically lowers the barrier for developer adoption, especially among those already using AI-enabled tools. However, consumer-facing applications like Claude Desktop still require manual configuration with JSON files, highlighting an increasingly apparent gap between developer tooling and consumer use cases.
Examples of MCP servers
The MCP ecosystem comprises a diverse range of servers including reference servers (created by the protocol maintainers as implementation examples), official integrations (maintained by companies for their platforms), and community servers (developed by independent contributors).
Reference servers
Reference servers demonstrate core MCP functionality and serve as examples for developers building their own implementations. These servers, maintained by MCP project contributors, include fundamental integrations like:
Git: This server offers tools to read, search, and manipulate Git repositories via LLMs. While relatively simple in its capabilities, the Git MCP reference server provides an excellent model for building your own implementation.
Filesystem: Node.js server that leverages MCP for filesystem operations: reading/writing, creating/deleting directories, and searching. The server offers dynamic directory access via Roots, a recent MCP feature that outlines the boundaries of server operation within the filesystem.
Fetch: This MCP server provides web content fetching capabilities. This server converts HTML to markdown for easier consumption by LLMs. This allows them to retrieve and process online content with greater speed and accuracy.
Official MCP integrations
These servers are officially supported by the companies who own the tools. Integrations like these are production-ready connectors available for immediate use.
Stripe: This integration can handle use cases like generating invoices, creating customers, or managing refunds through natural language requests. Here, the main draw is the potential for delegating payment concerns to customer-facing chatbots.
Supabase: This official MCP server allows users to interact with Supabase through an LLM: creating tables, querying data, deploying edge functions, and even managing branches. As an added security measure, Supabase MCP employs a SQL result wrapper to discourage LLMs from obeying malicious commands hidden in the data.
Apify: Through the use of over 4,000 Apify Actors, enables a wide range of functions including a RAG (Retrieval Augmented Generation) web browser, data scraping across multiple platforms, and content crawling.
Community MCP servers
The community-driven ecosystem exemplifies how standardization can accelerate adoption and creativity. The following servers are maintained by enthusiasts rather than businesses, which means they trend toward a more diverse range of needs.
Discord: The gaming-focused messaging app Discord shares many similarities with Slack, and the MCP server integration is no different. This allows users to send and read messages, with automatic server and channel discovery for easier navigation.
Docker: Enables natural language interaction with Docker to manage containers, volumes, and images. Intended for server admins and tinkerers, this abstracts Docker both local and remote engine management into a friendlier interface.
HubSpot: This integration with ubiquitous CRM HubSpot allows users to list and create contacts, get recent engagements, and manage companies. While simple, this server provides a simple way to retrieve information for use with other tools.
Security considerations for MCP servers
The rapid adoption of MCP has opened numerous, critical security challenges. Research by Knostic in July 2025 involved scanning nearly 2,000 MCP servers exposed to the internet, with all verified servers lacking any form of authentication. This essentially means anyone could access internal tool listings and potentially exfiltrate sensitive data. Similarly, Backslash Security’s June 2025 findings identified similar vulnerabilities in another 2,000 servers, noting patterns of over-permissioning and complete exposure on local networks.
The June 2025 update to the MCP authorization specification addresses some concerns by classifying MCP servers as OAuth Resource Servers, while requiring clients to implement Resource Indicators (RFC 8707). This intends to prevent malicious servers from obtaining access tokens, but implementation remains inconsistent. The MCP auth spec can’t really solve these issues if implementers don’t actually add security.
One cautionary tale of over-permissioning emerged in July 2025, when Replit’s AI agent deleted a production database containing over 1,200 records. This was in spite of explicit instructions (a “code and action freeze”) meant to prevent any changes to production systems. The lesson in this appears to be that proper permissioning, had it been handled via OAuth scopes externally, might have saved their code.
For comprehensive guidance on MCP authentication and authorization, see Descope’s MCP auth spec guide, and for enterprise deployment considerations, refer to our enterprise MCP challenges article.
Ultimately, human-in-the-loop design remains crucial to keeping LLMs in their appropriate roles, avoiding painful misfires. Clients must request explicit permission before accessing tools or resources, but this protection depends on specific permission prompts—and users understanding the impact of their choices.
Conclusion
The Model Context Protocol represents a significant leap in connecting LLMs to external systems, standardizing a fragmented ecosystem and potentially resolving the NxM problem. By universalizing how AI applications talk to tools and data sources, MCP reduces development overhead and enables a more interoperable ecosystem where innovation benefits the entire community—rather than remaining siloed.
As MCP continues to progress as a standard, several new developments have appeared on the horizon:
Secure elicitation: The current elicitation mechanism is only for gathering non-sensitive information from users through structured, in-band requests. This proposed new
urlmode for the elicitation capability would secure out-of-band interactions that bypass the MCP client, addressing scenarios such as gathering credentials and handling payments without exposing sensitive data to the MCP client.Progressive scoping: Scoping recklessly can lead to a variety of risks, including malicious incidents. Progressive scoping instead looks at the intent of a tool (what it wants to do) and whether it has permission to do so. This proposed change would introduce an MCP-specific field for a
scopes_defaultextension for Protected Resource Metadata (PRM), while defining a scope error handling strategy.Client ID metadata documents: This proposed change addresses a common MCP scenario in which servers and clients have no pre-existing relationship, mainly due to its reliance on two registration policies: pre-registration, and Dynamic Client Registration (DCR). Both pose significant drawbacks in execution. Client ID metadata documents could reside at specific HTTPS URLs, and OAuth clients could use these URLs as client identifiers. This would enable servers to trust previously unknown clients while retaining total control over authorization policy.
While these upcoming additions will further cement MCP’s role in making AI development faster and easier, the protocol has already made a huge impact on the LLM ecosystem. Providing a common format for integrations amounts to more than speeding up the processes we already have. It has created a space where both major enterprises and individual contributors can build equally viable, increasingly valuable options to make everyone’s lives better.
For more developer updates from the world of authentication, access control, and AI, subscribe to our blog or follow us on LinkedIn. If you’re building MCP servers and looking for identity infrastructure that accelerates their time to production while enhancing security, check out our MCP Auth SDKs.



