

Table of Contents
As systems move toward open, federated models, developers need a way for clients to talk to authorization servers they’ve never encountered before. Many architects embraced Dynamic Client Registration (DCR), but this quickly exposed some fundamental flaws with the method.
How do you trust and authorize clients when servers and clients have never seen each other before?
Whether it's Fediverse users trying to connect to a new instance or MCP clients registering with a new server, the same problem applies: How do you trust and authorize clients when servers and clients have never seen each other before?
This “new” mechanism for a client identifying themselves as a URL has been in use by IndieAuth for over a decade and was recently adopted by BlueSky’s OAuth API. With CIMD, instead of registering with every new server, clients simply host their metadata at a stable HTTPS URL. The recent surge of interest in the Model Context Protocol (MCP) has further galvanized the desire for DCR alternatives—likely the main driver in the OAuth Working Group adopting it.
In this article, we’ll explore:
What Client ID Metadata Documents (CIMD) are
How CIMD addresses problems with the DCR method
How the Model Context Protocol (MCP) will use CIMD
What security challenges are present in CIMD systems
How the future of CIMD implementation will look
What are Client ID Metadata Documents (CIMD)?
A Client ID Metadata Document (CIMD) is a JSON document hosted at an HTTPS URL that allows an OAuth client to identify itself to an authorization server without pre-registration.
Picture this: A user wants to connect to a self-hosted instance on a decentralized service like Mastodon. These ecosystems don’t have a single main server to register OAuth clients, so manual pre-registration would be the traditional way of handling this. But it’s typically impossible when the client has no prior relationship with the authorization server.
The default solution for a while was DCR, which allows clients to register programmatically. DCR enables clients to discover authorization servers and their registration endpoints, receive credentials, and use them immediately for standard OAuth/OIDC flows. But DCR is ultimately an “open” registration system, meaning anyone can attempt to register (including threat actors).
This is where CIMD comes in, offering an alternative means for identifying clients without needing a prior relationship. Here’s how CIMD and DCR stack up as auth approaches:
| CIMD | DCR |
|---|---|---|
How clients register | Client hosts JSON metadata at an HTTPS URL it controls | Client hosts JSON metadata at an HTTPS URL it controls |
How the server stores client data | Fetches and caches metadata on demand; no persistent record | Stores each registration in a server-side database |
How identity is evaluated | Server confirms the metadata URL's origin matches the claimed client_id | Server accepts any valid registration payload without verifying ownership |
How clients expire | Metadata removal or URL takedown automatically invalidates the client | Requires explicit revocation or cleanup of stale database entries |
What the client needs | A domain with HTTPS hosting | Access to the server's registration endpoint |
How CIMD works
Client ID Metadata Documents allow OAuth clients to identify themselves to authorization servers by using a URL as the client_id. In this implementation, the URL refers to a JSON document containing the necessary metadata. Instead of asking the server to store information about the client, the client hosts that information itself and tells the server where to find it.
In “URL as identity,” domain ownership functions as implicit proof of control.
The diagram below illustrates the process with the following OAuth steps on success.
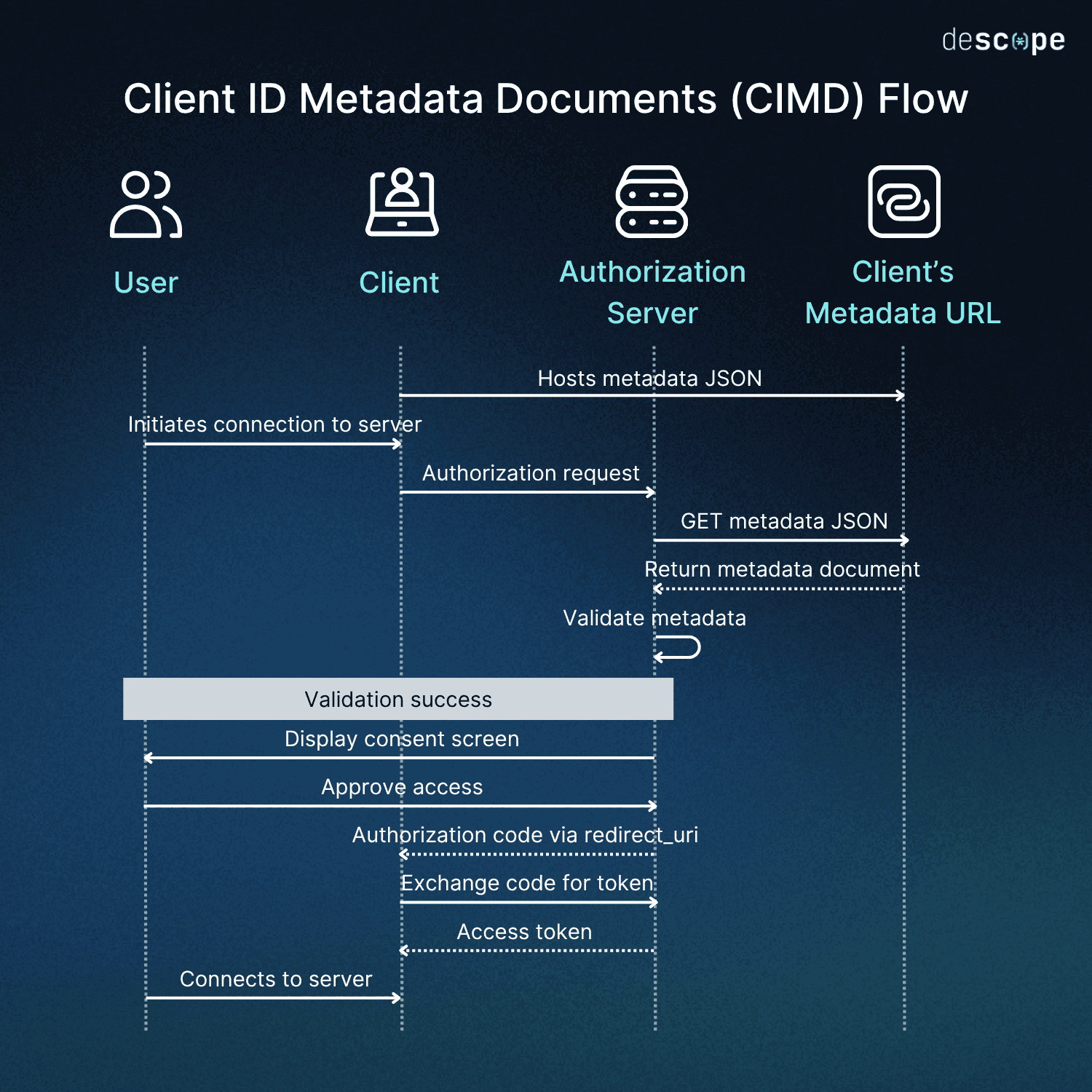
The CIMD flow can be broken down into four main steps. We’ll be using an MCP client for our example:
Client hosts metadata JSON: First, the client must host a JSON document with their metadata (client name, redirect URIs, logo) at an HTTPS URL. Note that the client’s ID doesn’t identify the specific user, just the client. For example, all Claude Desktop users would have the same JSON, and all Cursor users would have the same JSON. Here’s what an MCP client like Claude Desktop might use for its metadata at (for example)
https://claude.ai/mcp/oauth/metadata.json:
{
"client_id": "https://claude.ai/mcp/oauth/metadata.json",
"client_name": "Claude Desktop",
"client_uri": "https://claude.ai".
"logo_uri": "https://claude.ai/logo.png"
"redirect_uris": ["https://claude.ai/mcp/oauth/callback"],
"grant_types": ["authorization_code"],
"response_types": ["code"],
"token_endpoint_auth_method": "none"
}Client uses URL as client_id : Instead of using a pre-registered client ID, the client passes the metadata URL directly as the
client_idin the authorization request. When the MCP client initiates an OAuth flow to connect to a new server, it uses that JSON.Server fetches and validates JSON: The authorization server fetches the JSON from the URL and validates it, checking JSON structure, required fields, ensuring the
client_idmatches the source URL, enforcing size limits, and verifying redirect URIs are allowlisted. A successfully validated metadata document is then cached for a predefined period.Server initiates user consent and authorization: If the validation succeeds, the user is shown a consent screen with the appropriate name and logo. Here, they can approve access and their client can receive the necessary authorization code, which is then exchanged for an access token. The user is now connected.
CIMD provides built-in protection against client impersonation because the authorization server can verify that the client_uri has the same origin as the CIMD URL. This is because because the server can compare where the metadata was fetched from (the HTTPS origin) with what the client claims to be.
If a malicious actor tries to claim a fake identity by hosting a fake document at a similar-looking URL, the server can detect the mismatch between the hosting domain and the claimed identity.
For example, imagine a fake “Claude Desktop” at https://claude-desktop-login.net/.... If a client uses this domain, it won’t match the real https://claude.ai/…, and the server can reject the connection or downgrade trust.
For clients using custom URI schemes, servers SHOULD validate the scheme against the metadata but MUST NOT rely on web-origin matching. Instead, they should maintain an explicit allowlist of redirect URIs for that client.
CIMD technical considerations
The main step for CIMD clients to take is simply hosting the well-known URI. While most MCP clients are tied to applications that already have domains that can easily host a metadata document, that’s not the case for all CIMD use cases. Smaller teams and developers may have an app and a GitHub repository, but not a domain. This is a small hurdle, but a foundational one.
When it comes to actually hosting the metadata document, the current IETF specification draft, which has been adopted by the OAuth Working Group, defines a strict set of requirements for CIMD URLs:
Uses HTTPS
Contains a path component
Does not contain single-dot or double-dot path segments
Does not contain a username or password
Additionally, the client metadata document must contain a client_id property with a value matching the URL of the document using simple string comparison, as defined in RFC 3986.
One technical concern in CIMD is the problem of latency. Fetching metadata on every authorization request could conceivably result in at least minor hiccups for each login. However, while authorization servers using CIMD no longer need to store innumerable client registrations, the IETF spec indicates they may define their own upper and lower bounds on acceptable cache lifetimes.
Additionally, the metadata is fetched only when a client initiates a new authorization flow and not on token refreshes or API calls. Thus, the impact on user experience is effectively negligible.
In practice, servers typically cache metadata documents for up to 24 hours, meaning the fetch only happens once per client per day (or less frequently). The server fetches the metadata over secure HTTPS, enforcing hard limits on size, timeouts, and which networks it can talk to. Because it has verified the document is safe, once validated, the server can cache the result so refetching on every login isn’t necessary.
How CIMD addresses problems with DCR
DCR presents several critical security and scaling issues that CIMD resolves, especially in the realm of MCP server implementation:
Domain ownership replaces open registration
DCR allows anyone (including malicious parties) to register and potentially appear as another, trusted entity because every registration generates a random client_id. Meanwhile, client names (e.g., “Cursor,” “Claude Desktop”) are essentially up for grabs, and a threat actor can POST the exact same client_name as a legitimate client.
CIMD provides native protection against client impersonation because the authorization server can verify that the client URI has the same origin as the CIMD URL. There's o more “stranger danger” from accepting arbitrary registrations. With CIMD, the client ID essentially is the URL.
Unburdened registration database storage
Clients use an HTTPS metadata URL as their client ID directly, and authorization servers can cache this temporarily as needed. There are no longer infinite registrations to store server-side, and no exponential lists numbering in the hundreds of thousands. With CIMD, authorization servers simply fetch metadata when needed and cache it.
Natural client expiry and lifecycle
With CIMD, client validity is determined at request by fetching the metadata document. If it’s not available, auth fails. Metadata removal means automatic invalidation and no “stale” clients.
The impact is twofold: better security via no more stale database entries accepting potentially compromised clients, and enhanced efficiency via minimal (if any) complex cleanup.
Simpler operational logic
Hosting a JSON file is trivial. Most MCP clients will already have a site where they publish downloads for desktop apps or their chat interface, and that same site can server the metadata document with next to zero extra effort. With no registration endpoints to secure and no database maintenance, it’s a development hurdle eliminated.
These characteristics make CIMD ideal for MCP, which, while still in its infancy, is a developer-centric protocol with both enterprise and hobbyist engineers deploying new projects around the clock. Many of the challenges posed by DCR stymied enterprise adoption of MCP, and CIMD may be the catalyst that turns it around.
How MCP uses Client ID Metadata Documents (CIMD)
MCP has moved toward CIMD through SEP-991, and the latest MCP auth spec update introduces it as a suggested standard for client registration. In a nutshell, SEP-991 establishes CIMD as a preferred default (rather than DCR) within MCP.
It’s likely that CIMD will be the standard MCP client registration approach going forward.
CIMD specifically addresses the common MCP scenario where servers and clients have no pre-existing relationship. Adopting the method will enable servers to trust clients based on verified metadata while maintaining full control over critical security policies.
The current proposal is to make Client ID Metadata Documents the default for new MCP deployments, treating it as a “SHOULD” for servers. This prescription points toward a future of CIMD-first (or even only). However, at present, it reserves DCR as a “MAY” (and pre-registration optional where direct relationships exist) for cases in which the security variables aren’t a factor.
Ultimately, CIMD provides a standardized way for MCP servers to identify clients they have not previously encountered. It will likely significantly aid in the development of remote MCP servers, and may serve to boost enterprise adoption of the protocol.
The urgency is partly structural. Nearly all organizations say authentication will be critical to securing AI agent deployments, yet according to Descope's 2025 State of Customer Identity Report, fewer than four in ten have progressed beyond pilot stages. As agents connect to unknown servers and external tools at increasing rates, the gap between deployment ambition and identity infrastructure maturity makes lightweight, verifiable registration mechanisms like CIMD a practical necessity rather than a theoretical improvement.
Security challenges with CIMD
CIMD gives MCP developers and maintainers of decentralized ecosystems a significant advantage for registering previously unknown clients, but it’s not a silver bullet. CIMD is a sound strategy for many-to-many registration scenarios, while DCR remains a viable option for controlled environments when appropriately hardened against risks.
The shift toward CIMD is more about simplifying operational load than solving every identity challenge MCP faces. However, risks specific to CIMD remain, including but not limited to:
Localhost impersonation – If your client uses https://localhost redirect URIs, this is a well-established vulnerability in OAuth that’s exacerbated by MCP’s openness and can only be mitigated (not eliminated) by tactics like shortening the lifespan of JWTs. The hurdle of hosting the well-known URL as a client simply adds to this technical burden.
Server-Side Request Forgery (SSRF) – Because servers must now fetch from URLs, this type of attack allows a threat actor to access sensitive resources or actions by causing requests to originate from inside the server, which has much broader permissions than the client. Rate and size limits (no larger than the expected JSON) can deter abuse.
Meanwhile, the many other security challenges of MCP remain. One of the most prominent is tool poisoning, an MCP-specific form of prompt injection attack that targets large language models (LLMs) accessing MCP servers. Protections like short-lived tokens, fine-grained auth scopes, and other constraints help mitigate malicious instructions.
The path forward for client registration and MCP
With integration into OAuth’s and MCP’s official specifications, devs will soon be making registration lightweight while leaving space for stronger identity infrastructure as the ecosystem matures. CIMD won’t solve every auth challenge in MCP (or any decentralized system), but it eliminates the registration bottleneck that’s been holding developers and enterprises back.
CIMD won't solve every auth challenge in MCP (or any decentralized system), but it eliminates the registration bottleneck that's been holding developers and enterprises back. As adoption grows, the focus can shift from "How do we register previously unknown clients?" to the harder questions about authentication and authorization that remain—the next major milestones for MCP security.
For a deeper look at securing MCP auth flows in practice, see Tips to Harden OAuth Dynamic Client Registration in MCP Servers or Diving Into the MCP Authorization Specification. For more on agentic identity protocols, subscribe to the Descope blog.



